RNN lab
The main goal of this lab is to implement a model that is able to caption an image with a text that describes this image.
There will be 5 parts for this lab: Dataset description and pre-processing
Encoder: pre-trained CNN
Decoder: LSTM and Encoder-Decoder model
Training
Interference
Firstly, we describe our dataset: The one we use is COCO which is famous for object detection and image captioning. We will use here the 2014 version since it has 83k images for training, 41k for validation and 41k for test. In this laboratory we will only use 10k, 2k and 2k for respectively training, validation and testing.
For each set the data is separated in an image and a caption folder. Images are in JPG while captions are stored in a json file, this file specifies to which caption an image is linked.
The first step is to access this dataset:

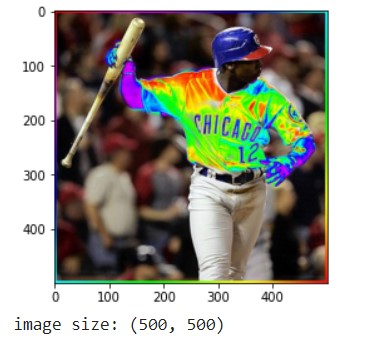
This is one of the images we displayed:
Then we linked images and captions:
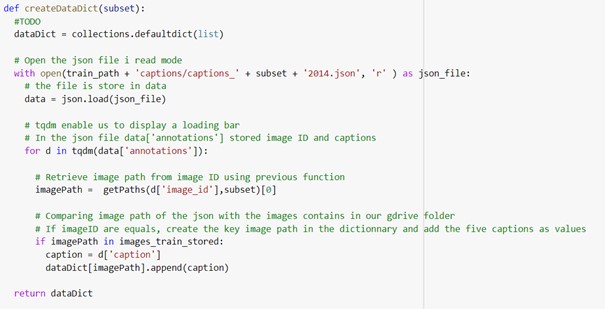
Thanks to this function we can load a dictionary.
Here is an example of captions linked to an image:

Then we create function that permit to retrieve words from these captions.
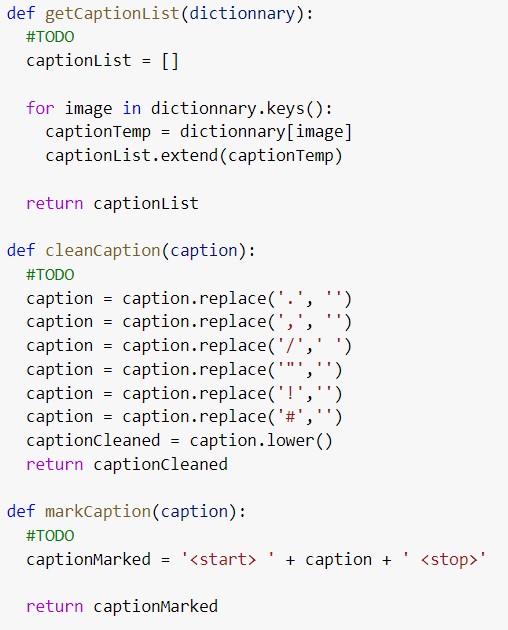
Then we compute a function that permit to retrieve the unique words.

This permit to get the vocabulary size. So we are able to turn words into vectors.


We also have to do the inverse operation:
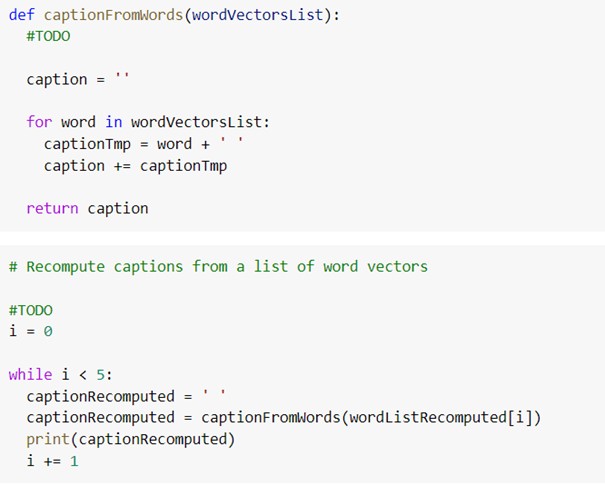
Encoder⌗
In this part we will implement our model that has to be composed of an encoder and a decoder. The encoder processes the input sequence and extracts features from it. These features will be decoded to produce the output sequence.
Our encoder is a pre-trained CNN on ImageNet.
After we need to encode images:

And then save these images from the encoder and load them from a pickle file.

Decoder⌗
We will use a LSTM as the decoder, it takes inputs = [images Features, captions] and outputs = next predicted words.
