Lab Reinforcement learning
Cart Pole⌗
This video explains the problem we try to solve using reinforcement learning.
On this page we will try to resume the lab we made in class and which parameter affect the efficiency of our model.
QNetwork:⌗
In this section we define our network which is a fully connected leyer.
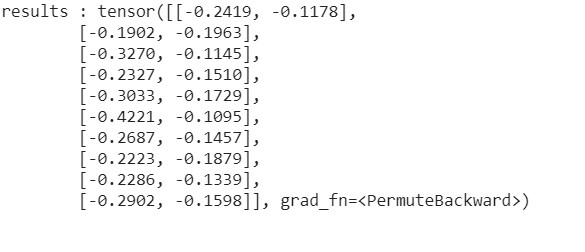
Results: it returns the value function at the current for the action 0 on the left and the action 1 on the right 10 times because there are 10 states (we take the max and the agent choose the value)
Doer:⌗
The doer represent things that do something (that act). It requires the model and has an epsilon (this is why here it acts randomly 10 percent of the time).
Then it choose the action from the max and return the action.

Experience replay:⌗
This is the part that permit to train the model and that defines the transition class.
It also introduces the notion of relevance which is connected to the loss of transition to make it more relevant.
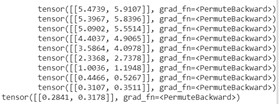
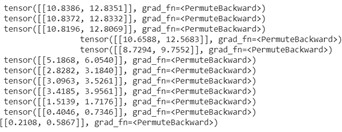
There is the output of this transition class (it gives all the information):

Now, concerning the experience replay class:
Its input is the list of transition, it deletes the less usefull transitions or the oldest ones when a transition is added.
The weights are uptaded with the relevance of the transition.
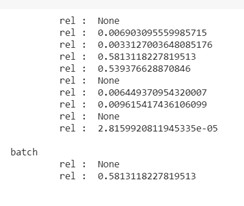
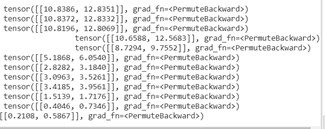
Then it samples a batch from thes transitions :
Learner⌗
The learner trains the Qlearner from batches of the experience replay, here we consider 2 algorithms : SARSA and Qlearning.
We get our network as a target (the one that is train)

We save a copy of it as a frozen network that we use as evaluation.

Weights are kept frozen to evaluate.
There are the 2 types of learning algorithms:

The target value is different for the 2 algorithms:
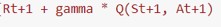
Then we wompute the loss function to update the target value.
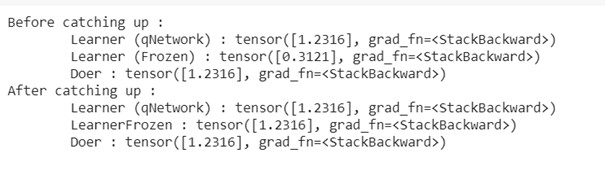
We test before train, during the train, and print the target and the frozen values.

This image shows the steps.

The next image is the illustration of the catching up of the frozen layer.
Training loop:⌗
This part is the most interesting one since this is here that we will change the parameters to see which of them affect the most our model.
This part starts by initializing all the previous blocks.

Then we have a list of experience replays:

This will influence the behavior, the result shows that the loss sometimes decreases and sometimes increases because the dataset is changing over time and so the score.
Evaluation:
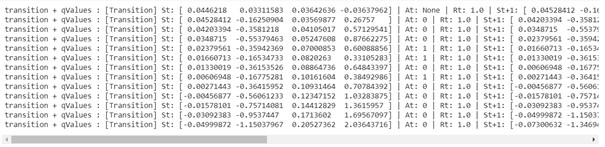
As you can see we have all the transitions.

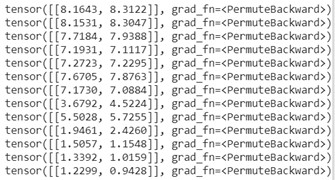
These are the rewards for choosing left or right in a current state, these are the values that are trained (the values go to 0 by the end of the episode and it has to be smooth).
Because of the 0 at the end it knows it will soon gonna fall.
Actually, we We want the previous vector to be one higher to the previous one, gamma tells us how many we need to go more later, we will go deeper in this topic later.
Experimentation:⌗
We will try to have the best result as possible, the highest score, by changing the component of the initialization of the training loop and the neural network.
Capacity (width):
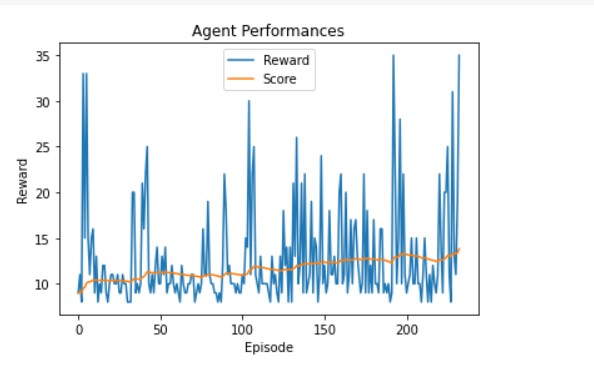
Width = 16

Width = 128
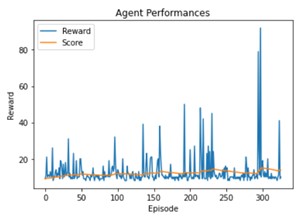
The training is slower and doesn’t have a higher score.
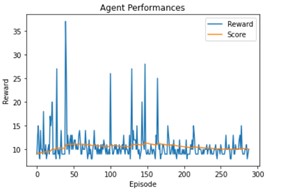
SARSA vs Qlearning
Here we used Qlearning instead of SARSA and we compare our next result with our last one with a width of 128.
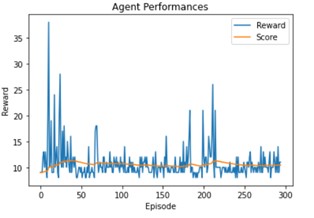
It improves significantly our model, the score is higher.
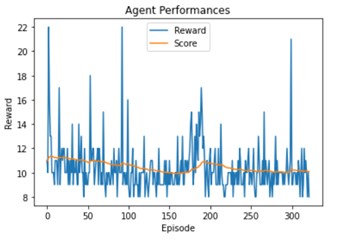
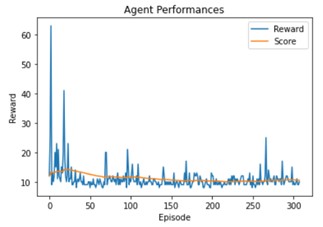
Buffer size
We use here a buffer size of 1024 here instead of 256 before:

This time the score is reduced.
Type of experience replays
We will test here different type of experience replays.
Sort transition = True means that it will remove the less relevant transition first instead of the oldest one (off-policy method).

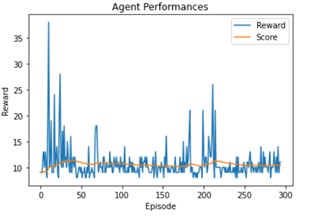

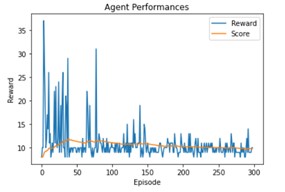




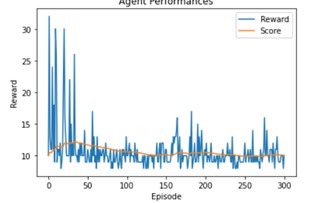

As we can see with the parameters we use they don’t have a strong influence by themselves, but if we combine them:

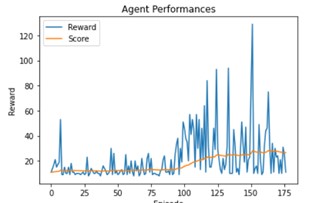

The result is significantly better.
The batch size is also a limiting factor, it has to be bigger to train on more data, it’s also what happened when we added an other exeperience replay.
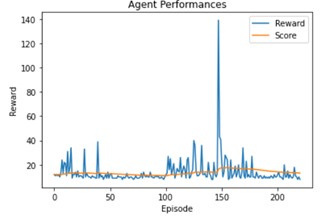
Here I used a batch size of 128 and the score is higher than with a smaller batch size.
So, these are the parameters to change in order to have a good model : an high width like 512, using the 4 experience replay with also big batch size such as 64.
Gamma parameter:
We want the value function target to be a certain factor higher to the previous one, gamma is this factor, it tells us how many we need to go more later:


Gamma will smooth the result and this is what we want.
This is a comparaison between gamma = 0.9:
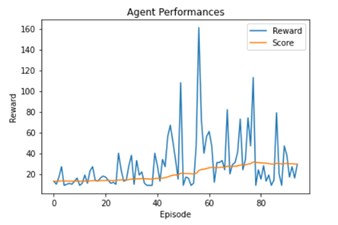
And gamma = 0.99:
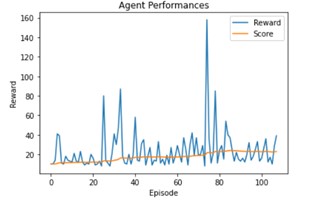

A good value for gamma is 0.90.